
Redis 数据结构:链表详解
链表
链表是除了数组之外,另一种广为人知的基础数据结构。
C 语言标准库并未内置链表,因此 Redis 实现了自定义的链表结构。
链表节点结构设计
首先,我们来看 Redis 中「链表节点」(listNode)的定义:
1 | typedef struct listNode { |
从 prev 和 next 指针可以看出,Redis 的链表是双向链表。
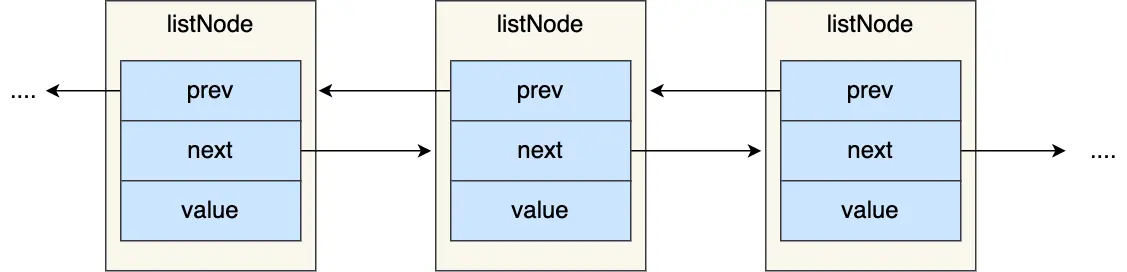
链表结构设计
在 listNode 的基础上,Redis 进一步封装了 list 结构体来管理整个链表,以方便操作。其定义如下:
1 | typedef struct list { |
list 结构包含了头指针 head、尾指针 tail、节点数量 len,以及三个函数指针:dup (用于复制节点值)、free (用于释放节点值)、match (用于比较节点值)。这些函数指针使得链表可以存储不同类型的数据并支持自定义操作,赋予了 Redis 链表更强的灵活性。
举个例子,下面是由 list 结构和 3 个 listNode 结构组成的链表。
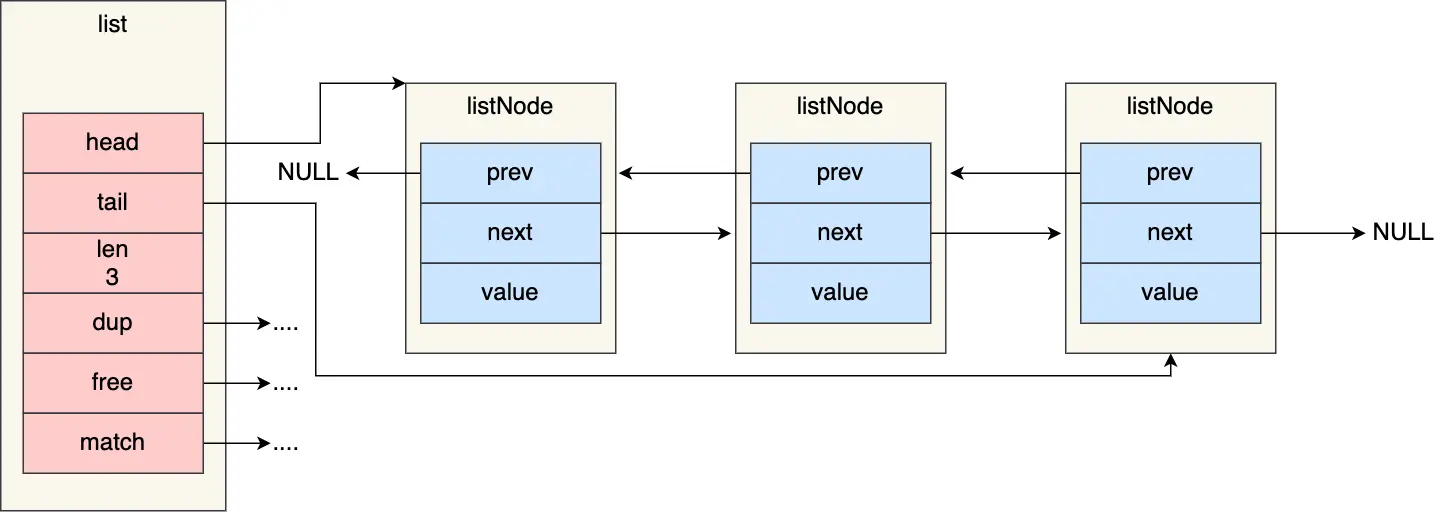
链表的优势与缺陷
Redis 的链表实现具有以下优点:
- 节点包含
prev和next指针,构成双向无环链表。这使得获取任意节点的前驱和后继节点的时间复杂度都是 O(1)。 - 通过
list结构中的head和tail指针,可以在 O(1) 时间内访问链表的头尾节点。 len属性使得获取链表长度的操作时间复杂度为 O(1)。- 节点值通过
void*指针保存,结合list结构中的dup、free和match函数指针,实现了多态链表,可以存储不同类型的数据并自定义处理逻辑。
链表也存在一些固有的缺陷:
- 节点的内存非连续分配,这降低了 CPU 缓存的命中率,影响访问效率。相比之下,数组由于其内存连续性,能更好地利用 CPU 缓存(基于空间局部性原理)。
- 每个节点除了存储数据外,还需要额外的空间存储前后指针(
prev和next),导致内存开销相对较大。
因此,在 Redis 3.0 版本之前,当 List 对象包含的元素较少时,会采用「压缩列表」(ziplist)作为其底层实现,以节省内存并利用其内存紧凑的特性。
然而,压缩列表在某些场景下存在性能瓶颈(例如连锁更新)。为此,Redis 3.2 版本引入了 quicklist,它结合了链表和压缩列表的优点,并成为 List 对象新的底层实现。
后续,Redis 5.0 推出了 listpack,它同样是一种紧凑的序列化数据结构,旨在替代压缩列表。在较新的 Redis 版本中,listpack 已被用于实现 Hash 和 Zset 对象的部分底层结构,逐步取代了原先的压缩列表。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2025-05-27
Redis 数据结构:QuickList 详解
全面介绍 Redis QuickList 的设计思想、内部结构和实现方式,分析其如何结合链表和压缩列表的优势,在 Redis List 类型中提供高效的存储和操作。

2025-05-21
Redis 数据结构:压缩列表详解
深入解析 Redis 压缩列表(ziplist)的设计原理、内存布局及优化策略,探讨其在 Redis 中的应用场景及如何实现高效的内存利用。
2025-05-21
Redis 数据结构:整数集合详解
详细讲解 Redis 整数集合(intset)的实现原理、升级机制和内存优化策略,分析其在 Redis Set 类型中的应用及如何平衡空间与时间效率。
2025-05-21
Redis 数据结构:哈希表详解
全面剖析 Redis 哈希表(Hash Table)的实现原理、扩容策略和渐进式 rehash 机制,解读其在 Redis 字典中的核心作用及性能优化手段。

2025-05-27
Redis 数据结构:ListPack 详解
深入分析 Redis 6.0 引入的 ListPack 数据结构,解读其设计目标、实现原理及对比压缩列表的改进,探讨其在 Redis 中替代 ziplist 的过程与优势。
2025-05-18
Redis基础 - 键值对数据库实现原理
深入解析Redis键值对数据库的实现原理,包括底层数据结构、键空间、数据存取机制以及性能优化策略,帮助理解Redis高性能的技术基础
Comments


