funcmapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { if h == nil || h.count == 0 { return unsafe.Pointer(&zeroVal[0]) } if h.flags&hashWriting != 0 { fatal("concurrent map read and map write") }
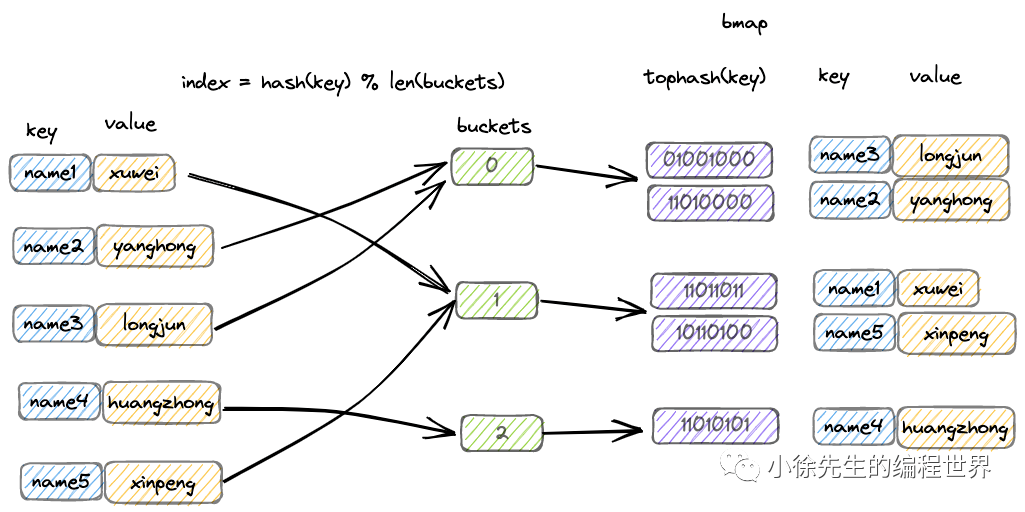
hash := t.hasher(key, uintptr(h.hash0)) m := bucketMask(h.B) b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil { if !h.sameSizeGrow() { m >>= 1 } oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize))) if !evacuated(oldb) { b = oldb } }
top := tophash(hash) bucketloop: for ; b != nil; b = b.overflow(t) { for i := uintptr(0); i < bucketCnt; i++ { if b.tophash[i] != top { if b.tophash[i] == emptyRest { break bucketloop } continue } k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) if t.indirectkey() { k = *((*unsafe.Pointer)(k)) } if t.key.equal(key, k) { e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) if t.indirectelem() { e = *((*unsafe.Pointer)(e)) } return e } } } return unsafe.Pointer(&zeroVal[0]) }
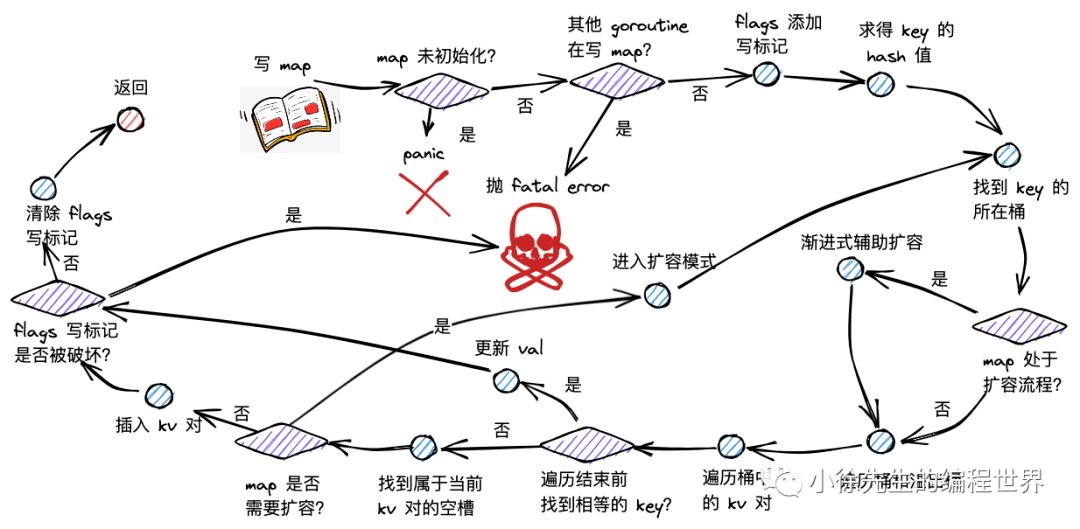
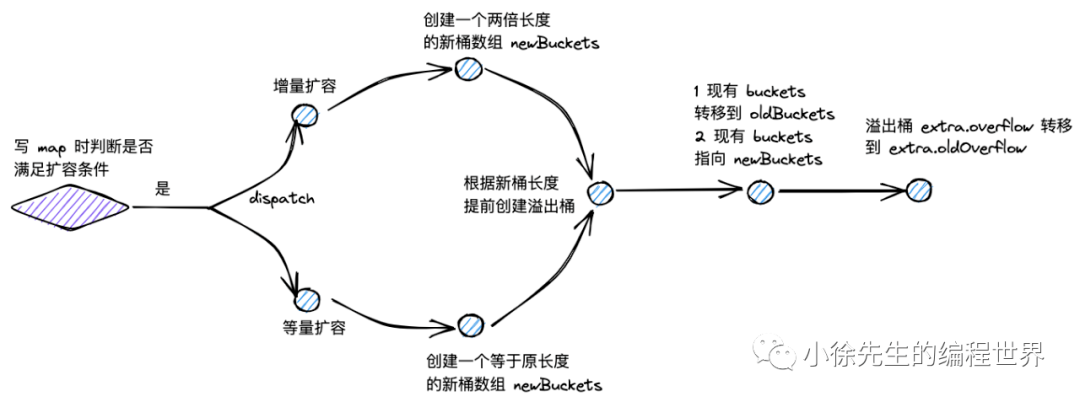
读流程详细步骤
1. 边界条件检查
1 2 3
if h == nil || h.count == 0 { return unsafe.Pointer(&zeroVal[0]) }
倘若 map 未初始化,或此时存在 key-value 对数量为 0,直接返回零值。
2. 并发安全检查
1 2 3
if h.flags&hashWriting != 0 { fatal("concurrent map read and map write") }
if c := h.oldbuckets; c != nil { if !h.sameSizeGrow() { m >>= 1 } oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize))) if !evacuated(oldb) { b = oldb } }
bucketloop: for ; b != nil; b = b.overflow(t) { for i := uintptr(0); i < bucketCnt; i++ { if b.tophash[i] != top { if b.tophash[i] == emptyRest { break bucketloop } continue } // 找到匹配的tophash,进一步比较完整key k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) if t.indirectkey() { k = *((*unsafe.Pointer)(k)) } if t.key.equal(key, k) { e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) if t.indirectelem() { e = *((*unsafe.Pointer)(e)) } return e } } }
funcmapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { if h == nil { panic("assignment to entry in nil map") } if h.flags&hashWriting != 0 { fatal("concurrent map writes") }
bucket := hash & bucketMask(h.B) if h.growing() { growWork(t, h, bucket) } b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize))) bOrig := b top := tophash(hash)
search: for ; b != nil; b = b.overflow(t) { for i := uintptr(0); i < bucketCnt; i++ { if b.tophash[i] != top { if b.tophash[i] == emptyRest { break search } continue } k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) k2 := k if t.indirectkey() { k2 = *((*unsafe.Pointer)(k2)) } if !t.key.equal(key, k2) { continue }