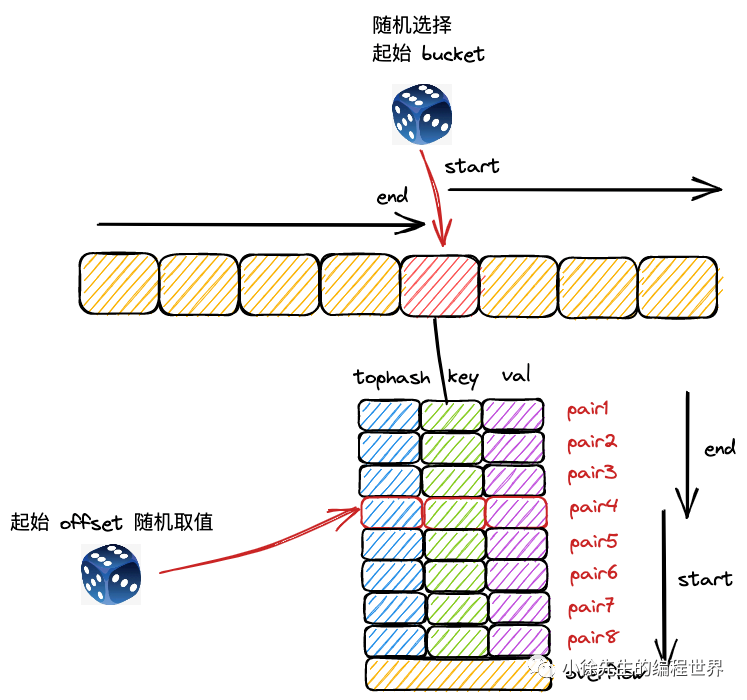
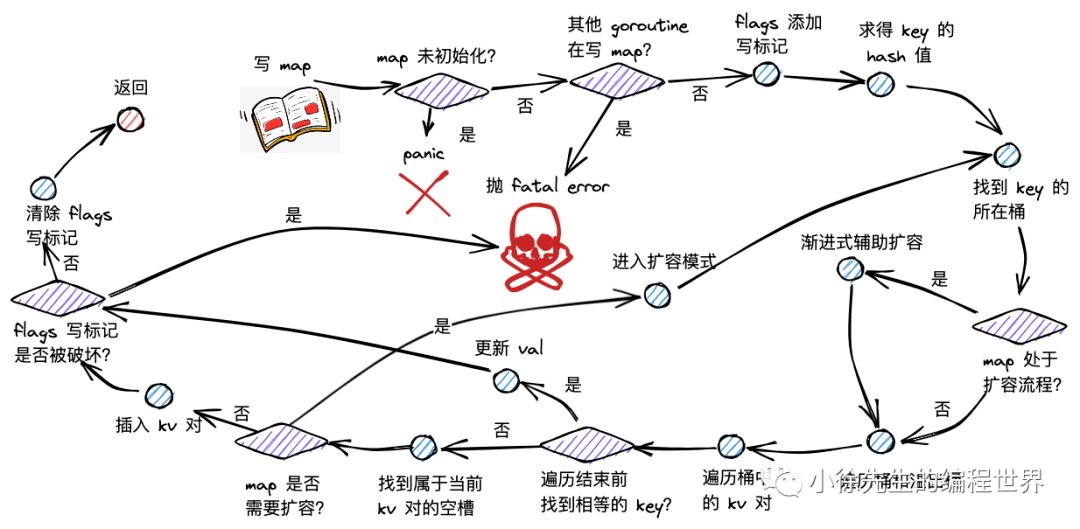
funcmapiternext(it *hiter) { h := it.h if h.flags&hashWriting != 0 { fatal("concurrent map iteration and map write") } t := it.t bucket := it.bucket b := it.bptr i := it.i checkBucket := it.checkBucket
next: if b == nil { // 检查是否完成一轮遍历 if bucket == it.startBucket && it.wrapped { it.key = nil it.elem = nil return }
// 处理扩容期间的遍历 if h.growing() && it.B == h.B { oldbucket := bucket & it.h.oldbucketmask() b = (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))) if !evacuated(b) { checkBucket = bucket } else { b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize))) checkBucket = noCheck } } else { b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize))) checkBucket = noCheck }
bucket++ if bucket == bucketShift(it.B) { bucket = 0 it.wrapped = true } i = 0 }
// 遍历桶内的 key-value 对 for ; i < bucketCnt; i++ { offi := (i + it.offset) & (bucketCnt - 1) // 应用随机偏移 if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty { continue }
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.keysize)) if t.indirectkey() { k = *((*unsafe.Pointer)(k)) } e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+uintptr(offi)*uintptr(t.elemsize))
// ❌ 错误:依赖遍历顺序 funcprocessMapInOrder(m map[string]int) { for k, v := range m { // 假设某种特定顺序进行处理 if isFirstKey(k) { // 这种假设是错误的 // ... } } }
// ✅ 正确:显式排序 funcprocessMapInOrder(m map[string]int) { keys := make([]string, 0, len(m)) for k := range m { keys = append(keys, k) } sort.Strings(keys)
for _, k := range keys { // 处理 m[k] } }
2. 避免遍历时修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// ❌ 错误:遍历时修改 for k, v := range m { if shouldDelete(v) { delete(m, k) // 会panic } }
// ✅ 正确:先收集后处理 toDelete := make([]string, 0) for k, v := range m { if shouldDelete(v) { toDelete = append(toDelete, k) } } for _, k := range toDelete { delete(m, k) }