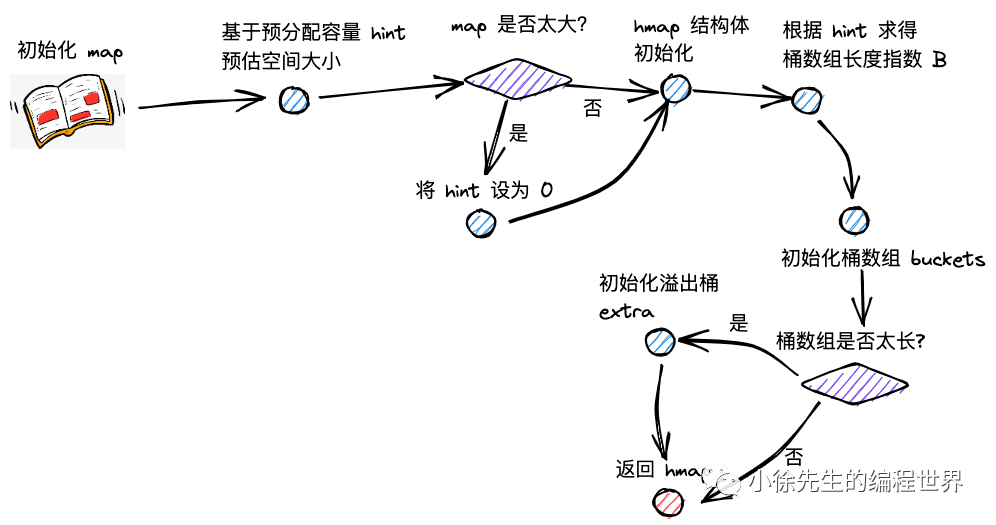
Go Map 面试题解析
基础概念类面试题
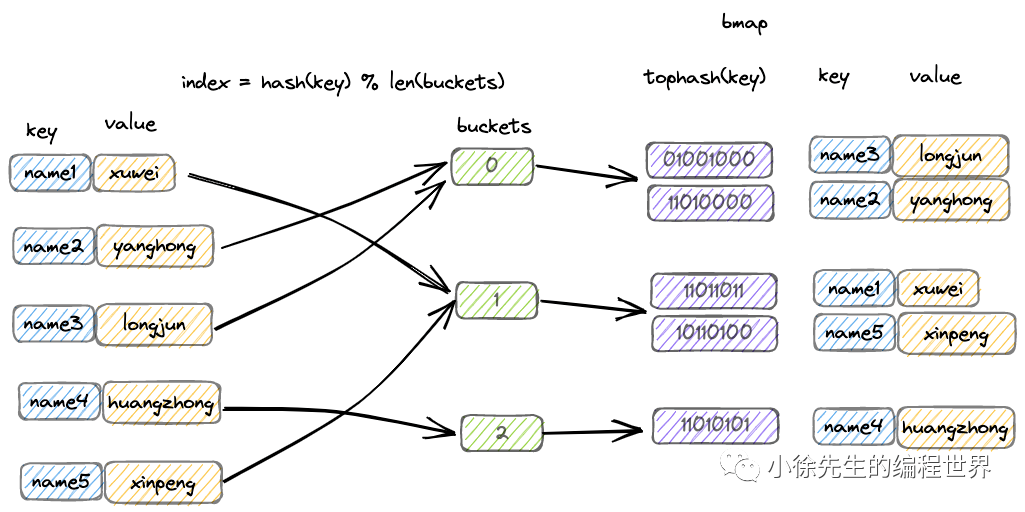
Q1: Go 语言中 map 的底层数据结构是什么?
A: Go 语言中 map 的底层数据结构是哈希表(hash table) ,具体实现包括:
hmap 结构体 :存储 map 的元数据,包括桶数组指针、元素数量、哈希种子等桶数组(buckets) :长度为 2 的整数次幂的数组,每个桶可存储 8 个 key-value 对溢出桶链表 :当桶满时,通过链表连接溢出桶解决哈希冲突渐进式扩容机制 :支持增量扩容和等量扩容
核心结构体:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 type hmap struct { count int flags uint8 B uint8 noverflow uint16 hash0 uint32 buckets unsafe.Pointer oldbuckets unsafe.Pointer nevacuate uintptr extra *mapextra } type bmap struct { tophash [8 ]uint8 }
Q2: Go map 如何解决哈希冲突?
A: Go map 采用拉链法 + 开放寻址法 的混合方式解决哈希冲突:
桶内开放寻址 :每个桶固定存储 8 个 key-value 对,发生冲突时在桶内寻找空位桶间拉链法 :当桶满时,通过溢出桶指针形成链表结构渐进式扩容 :当负载因子超过 6.5 时触发扩容,重新分布数据
解决冲突的步骤:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 hash := hasher(key, seed) bucket := hash & (bucketCount - 1 ) for i := 0 ; i < 8 ; i++ { if bucket[i] == empty { bucket[i] = key_value return } } overflowBucket := newOverflowBucket() linkToOverflow(bucket, overflowBucket)
Q3: Go map 的 key 有什么限制?
A: Go map 的 key 必须是可比较类型 :
可作为 key 的类型:
基本类型:bool, 数值类型, string
指针类型
数组类型(元素可比较)
结构体类型(所有字段可比较)
不可作为 key 的类型:
slice(切片)
map(映射)
function(函数)
原因: 这些类型无法用 == 操作符进行比较,无法计算稳定的哈希值。
1 2 3 4 5 6 7 8 9 m1 := make (map [string ]int ) m2 := make (map [int ]string ) m3 := make (map [[3 ]int ]string )
扩容机制类面试题
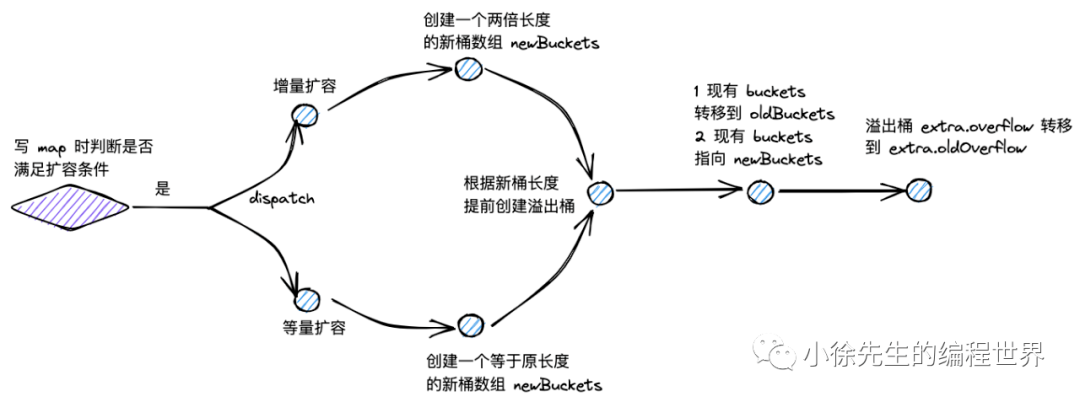
Q4: Go map 什么时候会扩容?扩容规则是什么?
A: Go map 有两种扩容触发条件:
增量扩容(容量翻倍):
触发条件:负载因子 > 6.5(即 count/2^B > 6.5)
扩容后:桶数组长度变为原来的 2 倍
目的:降低桶内元素密度,提高查找效率
等量扩容(容量不变):
触发条件:溢出桶数量 >= 2^B(B 最大为 15)
扩容后:桶数组长度不变,但重新整理数据
目的:减少溢出桶数量,提高内存利用率
扩容特点:
采用渐进式扩容,避免性能抖动
每次写操作时迁移 2 个桶的数据
通过 oldbuckets 和 buckets 双数组实现
1 2 3 4 5 6 7 8 9 10 11 12 func needGrow (h *hmap) bool { if overLoadFactor(h.count+1 , h.B) { return true } if tooManyOverflowBuckets(h.noverflow, h.B) { return true } return false }
Q5: Go map 扩容为什么是渐进式的?
A: 渐进式扩容的优势:
避免阻塞 :一次性迁移所有数据会导致长时间阻塞,影响程序响应性分摊开销 :将迁移开销分摊到多次操作中,单次操作延迟可控内存友好 :避免同时存在两份完整数据,减少内存峰值使用用户无感知 :对用户来说扩容过程透明
实现机制:
1 2 3 4 5 6 7 8 9 10 func growWork (t *maptype, h *hmap, bucket uintptr ) evacuate(t, h, bucket&h.oldbucketmask()) if h.growing() { evacuate(t, h, h.nevacuate) } }
并发安全类面试题
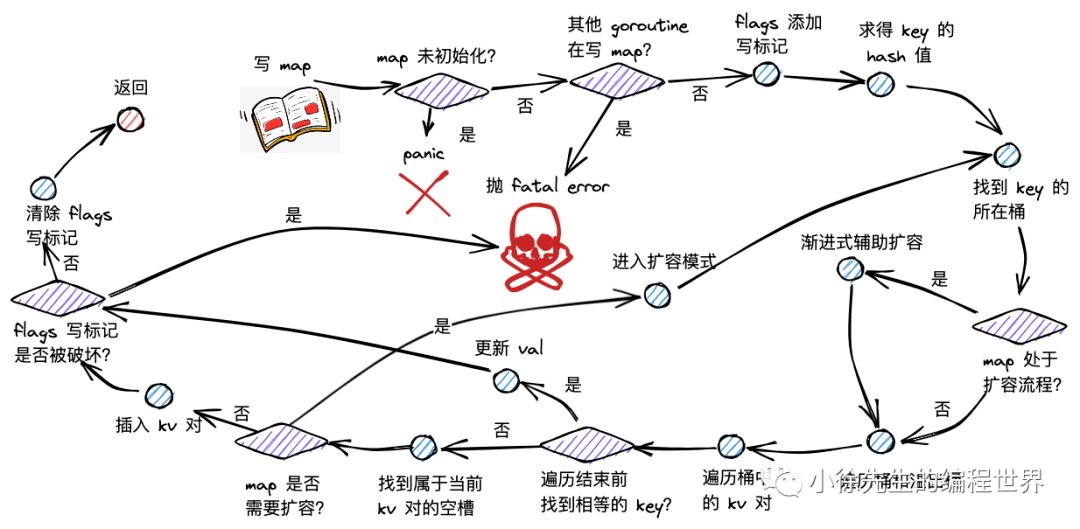
Q6: Go map 为什么不是并发安全的?如何解决?
A: Go map 不是并发安全的原因和解决方案:
不安全的原因:
设计理念 :为了性能考虑,Go map 没有内置锁机制检测机制 :运行时会检测并发读写,发现时抛出 fatal error性能优先 :避免为不需要并发的场景增加锁开销
并发检测规则:
并发读是安全的
读写并发会 panic:concurrent map read and map write
写写并发会 panic:concurrent map writes
解决方案:
方案 1:使用 sync.RWMutex 手动加锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 type SafeMap struct { mu sync.RWMutex m map [string ]int } func (sm *SafeMap) string , value int ) { sm.mu.Lock() defer sm.mu.Unlock() sm.m[key] = value } func (sm *SafeMap) string ) (int , bool ) { sm.mu.RLock() defer sm.mu.RUnlock() v, ok := sm.m[key] return v, ok }
方案 2:使用 sync.Map
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 var m sync.Mapm.Store("key" , "value" ) value, ok := m.Load("key" ) m.Delete("key" ) m.Range(func (key, value interface {}) bool { fmt.Println(key, value) return true })
方案 3:使用 channel 进行串行化访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 type MapService struct { m map [string ]int ch chan func () } func NewMapService () ms := &MapService{ m: make (map [string ]int ), ch: make (chan func () } go ms.run() return ms } func (ms *MapService) for f := range ms.ch { f() } } func (ms *MapService) string , value int ) { done := make (chan struct {}) ms.ch <- func () ms.m[key] = value close (done) } <-done }
性能优化类面试题
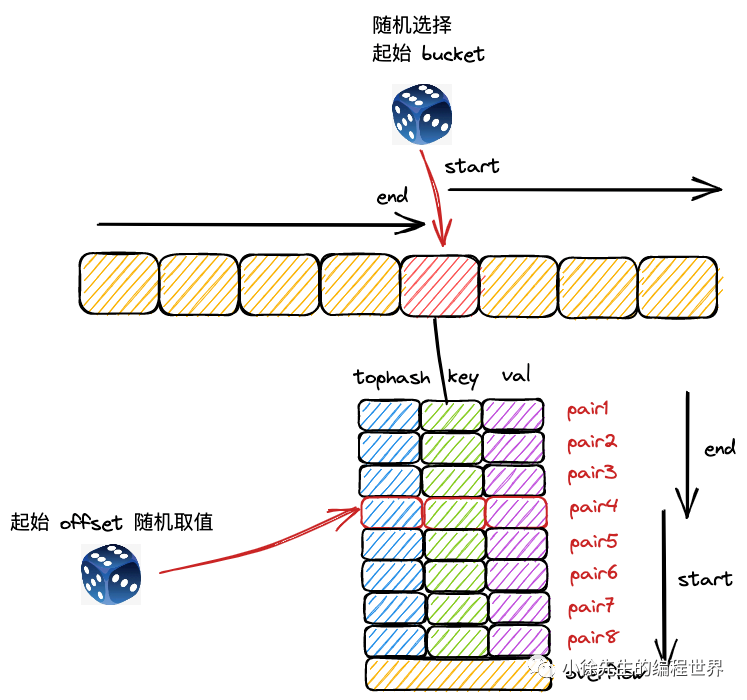
Q7: Go map 遍历为什么是无序的?如何实现有序遍历?
A: Go map 遍历无序的原因:
哈希表特性 :数据存储位置由哈希值决定,不保证顺序故意随机化 :Go 1.0 后故意引入随机化,防止程序依赖遍历顺序扩容影响 :扩容过程中数据重新分布,进一步打乱顺序
随机化实现:
1 2 3 4 5 6 func mapiterinit (t *maptype, h *hmap, it *hiter) r := uintptr (fastrand()) it.startBucket = r & bucketMask(h.B) it.offset = uint8 (r >> h.B & (bucketCnt - 1 )) }
实现有序遍历:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 keys := make ([]string , 0 , len (m)) for k := range m { keys = append (keys, k) } sort.Strings(keys) for _, k := range keys { fmt.Println(k, m[k]) } type OrderedMap struct { keys []string m map [string ]int } func (om *OrderedMap) string , value int ) { if _, exists := om.m[key]; !exists { om.keys = append (om.keys, key) } om.m[key] = value } func (om *OrderedMap) func (string , int ) for _, key := range om.keys { fn(key, om.m[key]) } }
Q8: 如何优化 map 的性能?
A: map 性能优化策略:
1. 预分配容量
1 2 3 4 5 6 7 8 9 10 11 m := make (map [string ]int ) for i := 0 ; i < 10000 ; i++ { m[fmt.Sprintf("key%d" , i)] = i } m := make (map [string ]int , 10000 ) for i := 0 ; i < 10000 ; i++ { m[fmt.Sprintf("key%d" , i)] = i }
2. 选择合适的 key 类型
1 2 3 4 5 6 7 m1 := make (map [string ]int ) m2 := make (map [interface {}]int ) m3 := make (map [int ]int ) m4 := make (map [uint64 ]int )
3. 避免频繁的删除操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 for key := range m { if shouldDelete(key) { delete (m, key) } } newM := make (map [string ]int , len (m)) for key, value := range m { if !shouldDelete(key) { newM[key] = value } } m = newM
4. 使用专门的数据结构
内存管理类面试题
Q9: Go map 的零值是什么?可以直接使用吗?
A:
零值 :Go map 的零值是 nil读操作 :可以从 nil map 读取,返回零值和 false写操作 :不能向 nil map 写入,会 panic:assignment to entry in nil map
1 2 3 4 5 6 7 8 9 10 11 12 var m map [string ]int fmt.Println(m == nil ) v, ok := m["key" ] m = make (map [string ]int ) m["key" ] = 1
正确初始化方式:
1 2 3 4 5 6 7 8 m1 := make (map [string ]int ) m2 := map [string ]int {"key" : 1 } m3 := make (map [string ]int , 10 )
Q10: 如何判断 map 中某个 key 是否存在?
A: 使用双返回值语法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 value, ok := m[key] if ok { fmt.Println("key存在,值为:" , value) } else { fmt.Println("key不存在" ) } if value, ok := m[key]; ok { fmt.Println("找到值:" , value) } if _, ok := m[key]; ok { fmt.Println("key存在" ) }
注意事项:
1 2 3 4 5 6 7 8 9 if m[key] != 0 { } if _, ok := m[key]; ok { }
高级应用类面试题
Q11: 遍历过程中修改 map 会发生什么?
A: 遍历过程中修改 map 的影响:
写操作冲突 :会触发 fatal("concurrent map iteration and map write")读操作安全 :同时多个遍历是安全的数据不一致 :即使不崩溃,也可能导致数据不一致
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 for k, v := range m { if shouldDelete(v) { delete (m, k) } if shouldUpdate(v) { m[k] = newValue } } toDelete := make ([]string , 0 ) toUpdate := make (map [string ]int ) for k, v := range m { if shouldDelete(v) { toDelete = append (toDelete, k) } if shouldUpdate(v) { toUpdate[k] = newValue } } for _, k := range toDelete { delete (m, k) } for k, v := range toUpdate { m[k] = v }
Q12: Go map 的内存泄漏问题及解决方案?
A: Go map 可能的内存泄漏问题:
问题 1:删除元素后内存不释放
1 2 3 4 5 6 7 8 9 10 11 m := make (map [string ][]byte , 1000000 ) for i := 0 ; i < 1000000 ; i++ { m[fmt.Sprintf("key%d" , i)] = make ([]byte , 1024 ) } for i := 0 ; i < 999000 ; i++ { delete (m, fmt.Sprintf("key%d" , i)) }
解决方案:
1 2 3 4 5 6 7 8 9 10 11 12 oldM := m m = make (map [string ][]byte , len (oldM)) for k, v := range oldM { m[k] = v } oldM = nil if len (m) < cap (m)/4 { }
问题 2:value 含有指针时的内存泄漏
1 2 3 4 5 6 7 8 type Node struct { data []byte next *Node } m := make (map [string ]*Node) delete (m, key)
解决方案:
1 2 3 4 5 6 7 8 9 10 if node, ok := m[key]; ok { for current := node; current != nil ; { next := current.next current.next = nil current = next } delete (m, key) }
实战应用类面试题
Q13: 实现一个并发安全的 LRU 缓存?
A: 基于 map + 双向链表实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 type LRUCache struct { capacity int cache map [int ]*Node head *Node tail *Node mutex sync.RWMutex } type Node struct { key int value int prev *Node next *Node } func NewLRUCache (capacity int ) head := &Node{} tail := &Node{} head.next = tail tail.prev = head return &LRUCache{ capacity: capacity, cache: make (map [int ]*Node), head: head, tail: tail, } } func (lru *LRUCache) int ) int { lru.mutex.Lock() defer lru.mutex.Unlock() if node, ok := lru.cache[key]; ok { lru.moveToHead(node) return node.value } return -1 } func (lru *LRUCache) int ) { lru.mutex.Lock() defer lru.mutex.Unlock() if node, ok := lru.cache[key]; ok { node.value = value lru.moveToHead(node) return } node := &Node{key: key, value: value} lru.cache[key] = node lru.addToHead(node) if len (lru.cache) > lru.capacity { tail := lru.removeTail() delete (lru.cache, tail.key) } } func (lru *LRUCache) lru.removeNode(node) lru.addToHead(node) } func (lru *LRUCache) node.prev.next = node.next node.next.prev = node.prev } func (lru *LRUCache) node.prev = lru.head node.next = lru.head.next lru.head.next.prev = node lru.head.next = node } func (lru *LRUCache) last := lru.tail.prev lru.removeNode(last) return last }
Q14: 如何实现一个支持过期时间的 map?
A: 带过期时间的并发安全 map:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 type ExpiringMap struct { data map [string ]*Item mutex sync.RWMutex stop chan struct {} } type Item struct { value interface {} expireAt time.Time } func NewExpiringMap (cleanupInterval time.Duration) em := &ExpiringMap{ data: make (map [string ]*Item), stop: make (chan struct {}), } go em.cleanup(cleanupInterval) return em } func (em *ExpiringMap) string , value interface {}, ttl time.Duration) { em.mutex.Lock() defer em.mutex.Unlock() em.data[key] = &Item{ value: value, expireAt: time.Now().Add(ttl), } } func (em *ExpiringMap) string ) (interface {}, bool ) { em.mutex.RLock() defer em.mutex.RUnlock() item, ok := em.data[key] if !ok { return nil , false } if time.Now().After(item.expireAt) { go em.delete (key) return nil , false } return item.value, true } func (em *ExpiringMap) delete (key string ) { em.mutex.Lock() defer em.mutex.Unlock() delete (em.data, key) } func (em *ExpiringMap) ticker := time.NewTicker(interval) defer ticker.Stop() for { select { case <-ticker.C: em.removeExpired() case <-em.stop: return } } } func (em *ExpiringMap) em.mutex.Lock() defer em.mutex.Unlock() now := time.Now() for key, item := range em.data { if now.After(item.expireAt) { delete (em.data, key) } } } func (em *ExpiringMap) close (em.stop) }
总结
Go map 的面试题涵盖了从基础概念到高级应用的各个方面:
基础原理 :理解哈希表、桶数组、冲突解决等核心概念扩容机制 :掌握渐进式扩容的原理和优势并发安全 :了解并发问题及各种解决方案性能优化 :掌握性能优化的技巧和最佳实践内存管理 :理解内存泄漏问题及解决方案实战应用 :能够基于 map 实现复杂的数据结构
深入理解这些知识点,不仅有助于通过面试,更重要的是能在实际工作中正确高效地使用 Go map。