
LeetCode 212 - 单词搜索 II(Word Search II)
问题描述
给定一个 m x n 二维字符网格 board 和一个单词列表 words,返回所有在二维网格中可以找到的单词。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中"相邻"单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
示例 1:
1 | 输入:board = [["o","a","a","n"], |
示例 2:
1 | 输入:board = [["a","b"], |
约束条件:
m == board.lengthn == board[i].length1 <= m, n <= 12board[i][j]是一个小写英文字母1 <= words.length <= 3 * 10^41 <= words[i].length <= 10words[i]由小写英文字母组成words中的所有字符串互不相同
解题思路
这道题是单词搜索问题的升级版,需要在同一个二维网格中搜索多个单词。如果我们对每个单词都进行一次 DFS 搜索,时间复杂度会非常高。因此,我们需要使用**字典树(Trie)**来优化搜索过程。
核心思路
关键洞见:使用字典树将所有目标单词存储在一个数据结构中,然后只需要对网格进行一次 DFS 遍历,在遍历过程中同时匹配字典树中的所有单词。
算法步骤
1. 构建字典树
- 将所有待搜索的单词插入到字典树中
- 在叶子节点存储完整的单词,便于识别完整匹配
2. DFS 搜索策略
- 从网格的每个位置开始进行 DFS
- 在 DFS 过程中,根据当前路径的字符在字典树中进行匹配
- 如果当前路径无法在字典树中继续匹配,则提前剪枝
- 如果匹配到完整单词,则记录结果
3. 回溯机制
- 使用标记字符(如
#)来避免在同一次 DFS 中重复访问相同位置 - 在 DFS 返回时恢复原始字符,确保不同路径可以重复使用相同位置
实现细节
字典树节点设计
1 | type Trie1 struct { |
DFS 搜索流程
- 边界检查:检查坐标是否越界或位置是否已访问
- 字典树匹配:根据当前字符在字典树中查找对应子节点
- 剪枝优化:如果字典树中没有对应子节点,直接返回
- 结果记录:如果当前节点包含完整单词,记录到结果中
- 标记访问:将当前位置标记为已访问(使用特殊字符)
- 递归搜索:向四个方向继续 DFS
- 恢复状态:回溯时恢复原始字符
代码实现
1 | type Trie1 struct { |
方法比较
| 方面 | 暴力解法 | 字典树 + DFS |
|---|---|---|
| 时间复杂度 | $O(k \cdot m \cdot n \cdot 4^L)$ | $O(m \cdot n \cdot 4^L)$ |
| 空间复杂度 | $O(L)$ | $O(\sum w_i)$ |
| 优点 | 实现简单 | 高效剪枝,减少重复搜索 |
| 缺点 | 重复搜索相同路径 | 需要额外的字典树空间 |
| 推荐度 | ★★☆☆☆ | ★★★★★ |
其中:
- $k$ = 单词数量
- $m \times n$ = 网格大小
- $L$ = 单词最大长度
- $\sum w_i$ = 所有单词的字符总数
复杂度分析
时间复杂度:$O(m \cdot n \cdot 4^L)$
详细分析:
- 字典树构建:$O(\sum w_i)$,其中 $\sum w_i$ 是所有单词的字符总数
- DFS 搜索:
- 从每个位置开始:$O(m \cdot n)$
- 每次 DFS 最多递归 $L$ 层(单词最大长度)
- 每层有 4 个方向选择:$O(4^L)$
- 字典树剪枝大大减少了实际搜索空间
总时间复杂度:$O(m \cdot n \cdot 4^L + \sum w_i)$,主要部分是 $O(m \cdot n \cdot 4^L)$
空间复杂度:$O(\sum w_i)$
空间使用分析:
- 字典树存储:$O(\sum w_i)$ - 存储所有单词的字符
- DFS 递归栈:$O(L)$ - 最大递归深度为单词长度
- 结果存储:$O(k \cdot L)$ - 最多 $k$ 个单词,每个长度 $L$
关键收获
算法技巧
- 字典树优化:将多个单词的搜索问题转化为单次遍历问题
- 剪枝策略:利用字典树的前缀特性提前终止无效路径
- 状态恢复:使用标记字符避免重复访问,回溯时恢复状态
常见陷阱
- 忘记回溯:必须在 DFS 返回时恢复原始字符
- 重复计数:使用
map[string]bool去重,避免同一单词被多次计算 - 边界处理:检查数组越界和已访问位置
扩展应用
- 单词游戏:如 Boggle 游戏的单词搜索
- 文本匹配:在大文本中搜索多个模式串
- 路径规划:在图中搜索满足特定模式的路径
这道题完美展示了字典树在多模式匹配中的强大作用,是掌握高级字符串算法的重要题目。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2025-06-29
LeetCode 211 - 添加与搜索单词-数据结构设计(Design Add and Search Words Data Structure)
使用字典树(Trie)实现支持通配符搜索的单词字典,关键在于递归DFS处理'.'字符的所有可能匹配
2025-06-22
LeetCode 399 - 除法求值:从图论到Floyd算法的优雅转换
深入探讨除法求值问题的多种解法:从直观的图论DFS到优雅的Floyd算法改进,揭示经典算法在新问题中的巧妙应用
2025-06-17
LeetCode 222 - 完全二叉树的节点个数(Count Complete Tree Nodes)
利用完全二叉树的性质,通过计算左右子树高度来优化节点计数,时间复杂度O(log²n)的高效解法
2025-06-21
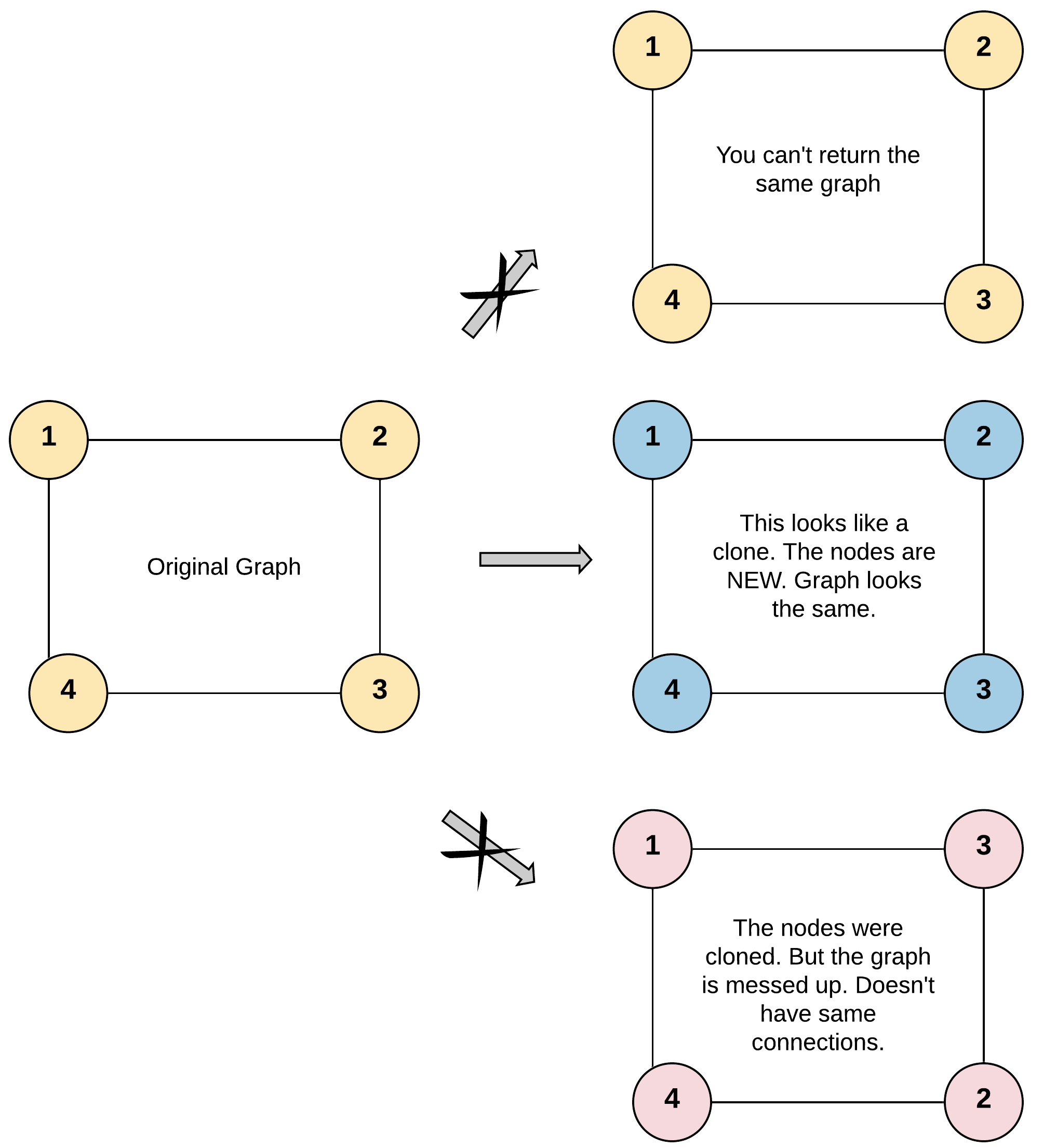
LeetCode 133 - 克隆图(Clone Graph)
深入解析图的深拷贝问题,使用DFS和哈希表避免环形引用,详细分析访问标记时机的重要性
2025-06-18
LeetCode 530 - 二叉搜索树的最小绝对差(Minimum Absolute Difference in BST)
利用二叉搜索树中序遍历有序性的特点,通过一次遍历找出相邻节点的最小绝对差值,时间复杂度 O(n),空间复杂度 O(h)
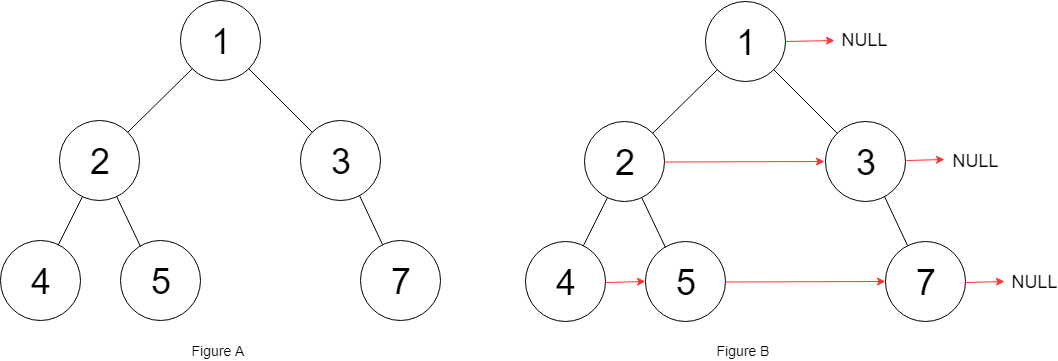
2025-06-15
LeetCode 117 - 填充每个节点的下一个右侧节点指针 II(Populating Next Right Pointers in Each Node II)
详解LeetCode 117题三种解法:哈希表DFS、层序遍历BFS、O(1)空间优化。通过图解和代码详细分析如何为二叉树每个节点填充下一个右侧节点指针。
Comments


