
Redis基础 - 键值对数据库实现原理
深入解析Redis键值对数据库的实现原理,包括底层数据结构、键空间、数据存取机制以及性能优化策略,帮助理解Redis高性能的技术基础

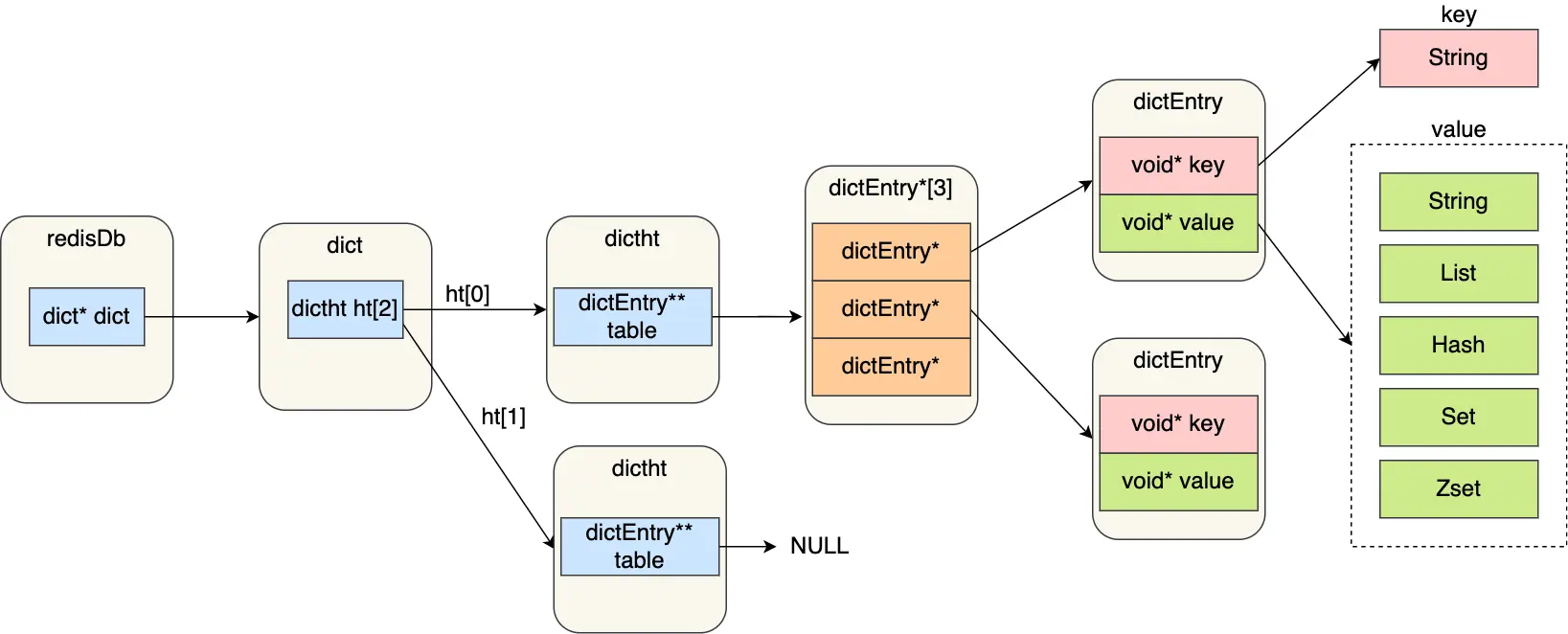
Redis 数据结构:SDS 详解
深入理解 Redis 中的动态字符串(SDS)的实现原理、优势以及与传统 C 字符串的区别,探索为什么 Redis 选择 SDS 而不是 C 语言原生字符串。
❌ LeetCode 32 - 最长有效括号:动态规划思路错题分析
详细分析 LeetCode 32题 '最长有效括号' 动态规划解法中一个常见的状态转移错误,并提供正确的思路和代码。
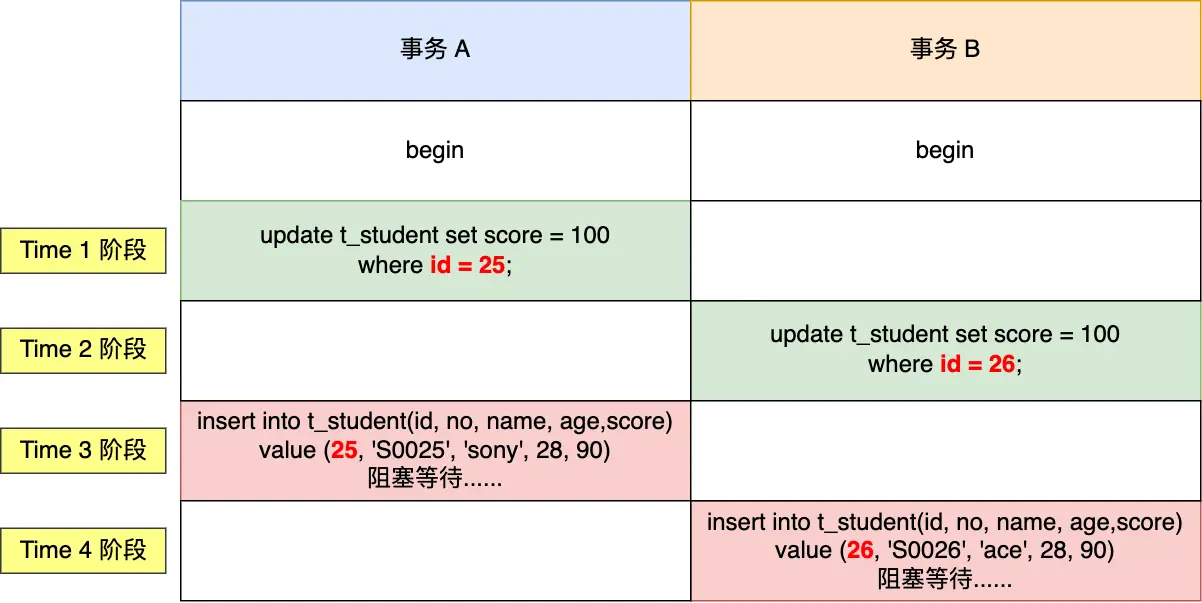
字节面试:加了什么锁,导致死锁?
深入分析MySQL中常见的锁机制,探讨不同锁类型如何导致死锁,并结合字节跳动面试题场景进行解析。
LeetCode 416 - 分割等和子集 (Partition Equal Subset Sum)
LeetCode 416 分割等和子集问题详解,使用动态规划(0/1背包问题)解决。判断一个数组是否可以分割成两个元素和相等的子集。
LeetCode 300: 最长递增子序列 - 动态规划与贪心优化
详细解析 LeetCode 300 '最长递增子序列' 问题的动态规划解法和更优的贪心算法结合二分查找的思路,并提供带有注释的 Go 语言实现。
LeetCode 139. 单词拆分:小白也能看懂的动态规划解法
详细解析 LeetCode 139 题`单词拆分`的动态规划解法。通过清晰的步骤、示例和代码注释,帮助初学者理解如何使用 DP 判断字符串是否可以由字典中的单词拼接而成。
LeetCode 152 - 乘积最大子数组 (Maximum Product Subarray)
LeetCode 152 乘积最大子数组的解题思路、代码实现和复杂度分析。这道题要求找到一个数组中乘积最大的非空连续子数组。
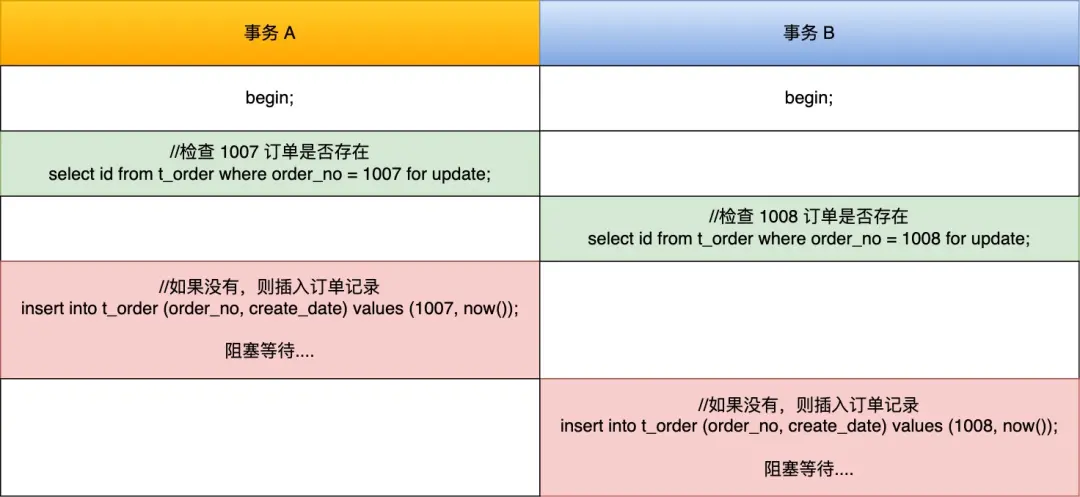
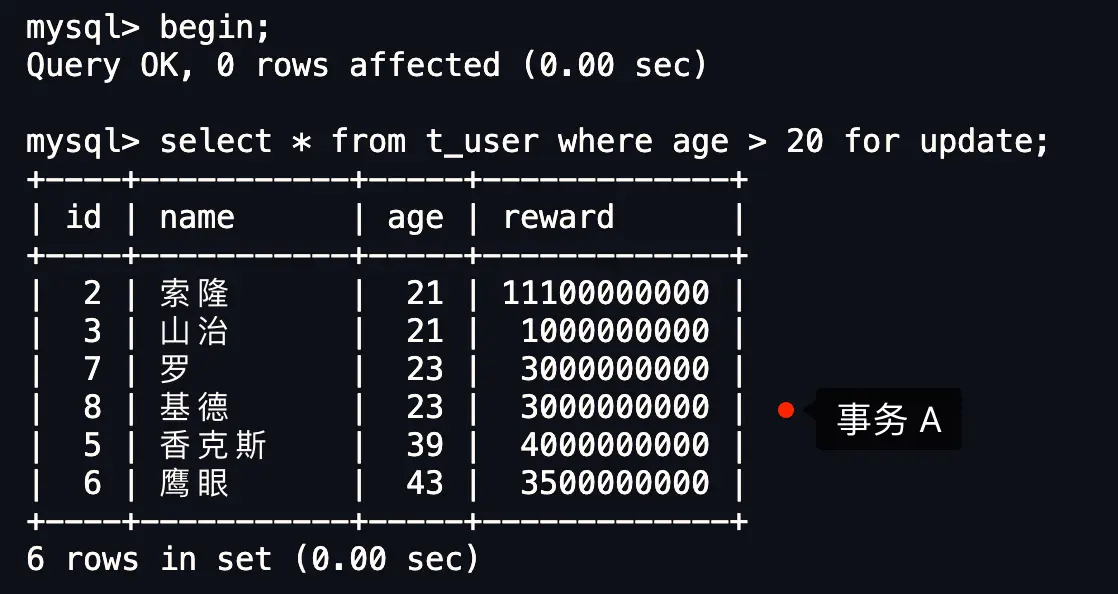
MySQL中的记录锁与间隙锁:能否抵挡删除操作引发的幻读?
本文将深入探讨 MySQL InnoDB 存储引擎在 REPEATABLE READ 隔离级别下,是如何巧妙运用记录锁、间隙锁以及 Next-Key 锁来防止因删除操作可能导致的幻读问题。


