
MySQL中update不带索引的危险:全表锁定详解
深入剖析MySQL中update语句不带索引的危险性,解释为什么会导致全表锁定,以及如何通过正确使用索引和安全更新模式来避免此类生产事故。
❌ LeetCode 322 - 零钱兑换
零钱兑换是一个经典的完全背包问题,本文分析了错误的解题思路以及两种正确的动态规划实现方式,包括自底向上的迭代法和自顶向下的记忆化搜索
LeetCode 763 - 划分字母区间(Partition Labels)
LeetCode 763 划分字母区间题解,使用贪心算法和双指针技术,通过记录字符最后出现位置实现最优划分,时间复杂度O(n),空间复杂度O(1)。
LeetCode 45 - 跳跃游戏 II (Jump Game II)
详解LeetCode第45题跳跃游戏II,通过贪心算法、动态规划和BFS三种方法分析如何高效求解最少跳跃次数问题,重点探讨贪心算法的实现技巧及优化思路

Redis BitMap及其他高级数据类型详解
详细解析Redis的BitMap、HyperLogLog、GEO和Stream等高级数据类型的实现原理、操作命令及应用场景,包括签到统计、用户在线状态、去重计数、地理位置服务和消息队列等实际应用
LeetCode 295 - 数据流的中位数(Find Median from Data Stream)
使用两个堆(最大堆与最小堆)巧妙维护数据流的中位数,实现了 O(log n) 的插入和 O(1) 的查询效率,并通过数据平衡策略确保中位数快速获取。
❌ LeetCode 215 - 数组中的第K个最大元素 (超时分析与优化)
对 LeetCode 215 题 “数组中的第K个最大元素” 的 Quick Select 解法进行超时分析,并提供优化后的正确题解,强调了算法关键点和可读性。
LeetCode 347 - 前 K 个高频元素 (Top K Frequent Elements)
本文详细介绍了 LeetCode 347 题“前 K 个高频元素”的解题思路,并重点讲解了如何在 Go 语言中使用 heap(优先队列)来解决此问题。
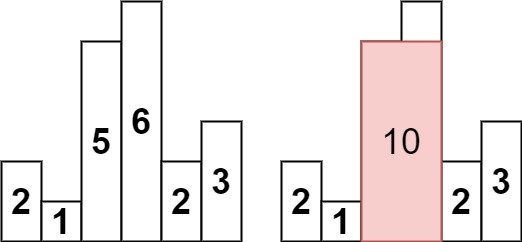
❌ LeetCode 84 - 柱状图中最大的矩形
深入剖析 LeetCode 84 柱状图中最大的矩形问题,通过暴力解法、分治法和单调栈三种不同方法解决,并详细分析单调栈解法中的常见错误
LeetCode 739 - 每日温度 (Daily Temperatures)
详细解析 LeetCode 739 题「每日温度」的解题思路,使用单调栈巧妙解决,并探讨代码优化,让你的代码更简洁。


