Loading...
Articles
175
Tags
243
Categories
48
首页
全部文章
八股文
Golang
MySQL
Redis
计算机网络
操作系统
架构
Leetcode题解
面试经验
关于我
Adrian Wang's blog
Search
首页
全部文章
八股文
Golang
MySQL
Redis
计算机网络
操作系统
架构
Leetcode题解
面试经验
关于我
Adrian Wang's blog
LeetCode 2 - 两数相加(Add Two Numbers)
Created
2025-04-23
|
算法刷题
LeetCode
链表
Model Context Protocol (MCP) 介绍
Created
2025-04-23
|
AI工程
MCP
MySQL 页类型详解
Created
2025-04-22
|
八股文
MySQL
存储原理
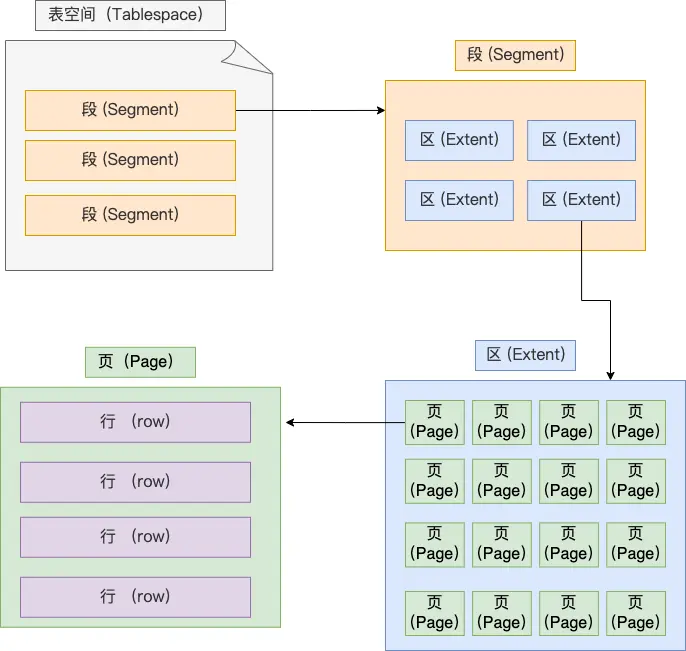
详细介绍MySQL InnoDB存储引擎中的各种页类型及其作用
MYSQL 记录存储方式
Created
2025-04-22
|
八股文
MySQL
存储原理
MYSQL 记录存储方式
LeetCode 142 - 环形链表 II (Linked List Cycle II)
Created
2025-04-22
|
算法刷题
LeetCode
链表
LeetCode 234 - 回文链表(Palindrome Linked List)
Created
2025-04-21
|
算法刷题
LeetCode
链表
LeetCode 206 - 反转链表(Reverse Linked List)
Created
2025-04-21
|
算法刷题
LeetCode
链表
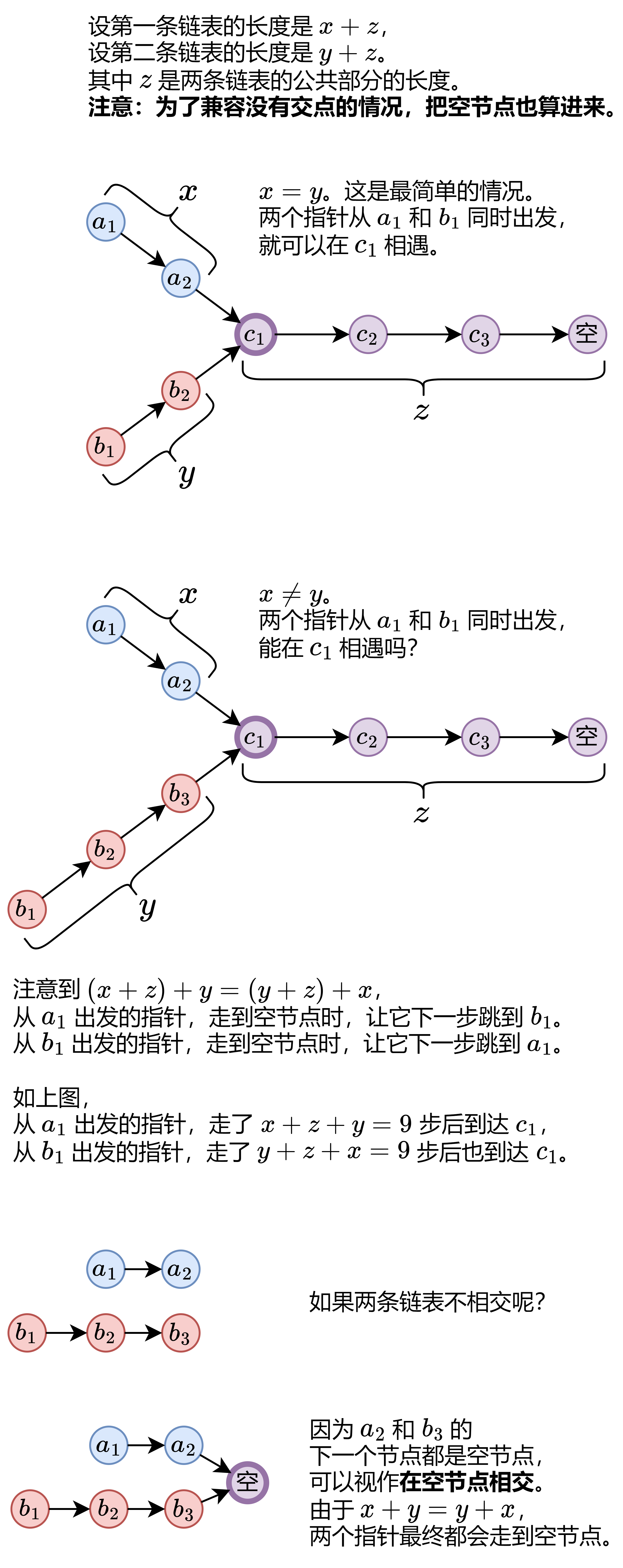
LeetCode 160 - 相交链表(Intersection of Two Linked Lists)
Created
2025-04-20
|
算法刷题
LeetCode
链表
LeetCode 240 - 搜索二维矩阵 II(Search a 2D Matrix II)
Created
2025-04-20
|
算法刷题
LeetCode
数组与哈希
LeetCode 2563 - 统计公平数对的数目(Count the Number of Fair Pairs)
Created
2025-04-20
|
算法刷题
LeetCode
数组与哈希
1
…
16
17
18
Adrian Wang
一个完全由AI生成,但是内容高质量的Blog
Articles
175
Tags
243
Categories
48
Follow Me
Announcement
欢迎来到 Adrian Wang 的博客!
Recent Posts
从单兵作战到团队协作:Claude Code Agent Teams 实战教程
2026-02-24
拒绝 AI 名词焦虑:LLM 核心概念,一次讲透
2026-02-13
温故知新——Golang GMP 万字洗髓经
2026-01-18
字节跳动 后端开发工程师 一面
2025-08-03
LeetCode 239 - 滑动窗口最大值(Sliding Window Maximum)
2025-07-26
Categories
AI
2
LLM
1
AI工程
2
AI Coding
1
MCP
1
八股文
61
Go语言
10
GMP
2
Map
7
垃圾回收
1
MySQL
22
事务
2
内存
1
存储原理
5
日志
1
索引
7
锁
6
Redis
25
内存管理
1
分布式锁
1
基础知识
2
持久化
3
数据类型
5
数据结构
8
缓存
2
高可用
3
操作系统
2
计算机网络
2
算法刷题
101
LeetCode
99
二分查找
5
位运算
2
动态规划
14
双指针
1
回溯
5
图论
4
堆
2
字符串
5
数学
3
数组与哈希
20
栈
5
树
13
模拟
7
错题集
1
贪心
4
链表
9
系统设计
1
面试经验
8
Tags
Claude Code
Agent
AI
教程
AI Coding
后端开发
工程效率
Trae
Skills
SubAgent
LLM
大模型
Prompt Engineering
Meta Prompt
二叉树
递归
迭代
深度优先搜索
广度优先搜索
Easy
LeetCode
Hot100
分治
哈希
Medium
动态规划
层序遍历
面试经典150
树
Hard
❌错题集
图
BFS
Go
性能优化
哈希表
回溯
DFS
贪心算法
数组
Archives
2026年02月
2
2026年01月
1
2025年08月
1
2025年07月
10
2025年06月
48
2025年05月
81
2025年04月
31
2024年07月
1
Website Info
Article Count :
175
Total Word Count :
468.5k
Unique Visitors :
Page Views :
Last Update :
Search
Loading Database